For the last few months I have been very busy developing and testing Reasonate within the BBSc303 ‘Digital Craft’ class at the VUW School of Architecture. The main purpose of the testing was to evaluate the adoption rate and usage trends of blogging and tagging within a simulated team design process. In concert with this goal the testing was also used to establish what sort of toolset design-orientated bloggers require, especially when operating within a structured environment of project groups, tutors (fellow students) and course coordinators (the lecturer, Mike Donn and myself).
In this test the ‘process’ is the digital modeling of an existing art gallery. The ‘design’ aspects are centred around the decisions the teams must make whilst modelling and rendering this existing building. The types of decisions ranged from the selection process of the gallery, choices on CAD standards and the moves made to overcome modelling/rendering issues during the project. Previous BBSc303 courses have run for the last eight years using a similar format, but rather than using a blogging system the design process documentation occurred at the end of the course and was presented in the form of a static HTML website (usually one or two pages linked together).
The major drawback of the process previously undertaken was the quantity of last minute, post-event justification that took place. Rather than documenting the actual processes as they happened the final submission was usually a last minute exercise outlining how things hypothetically occurred in an ordered fashion (whereas arguably most project decisions where more evolutionary or accidental in nature).
The functional purpose of Reasonate was to get students blogging their activities as they happened. In the course introduction guidelines on exactly how this blogging should be undertaken (in terms of frequency and content) were deliberately left open for interpretation. What was made clear however was that the marking process would only concentrate on Reasonate submitted content so the obligation was on the students to get as much online as they felt comfortable with in order to qualify for marks. In a follow up lecture nine weeks after the beginning of the course further emphasis was placed on the story-telling requirements of the process after observation that many blogs had a very strong scrapbook feel to them.
Functionality
Reasonate was developed as a web application and made available for student use within and outside of the University at http://www.reasonate.co.nz. For the testing process Reasonate had to support the following functionality in order to satisfy course requirements:
Identity of students and flexible project groups
Arguably the most important feature of the system was the ability to create student identities that could then be associated into project teams. Creation and basic management of project teams were left up to students to perform whilst the administrator (Mike Donn) held final sway as to whether the proposed project and student combination was accepted or not. The project construct aggregated the blogs of the participating students. This aggregation generated project blogs that were the sum of all the student blogs associated to a particular subject. This aggreated blog system is very similar to the philosophy behind the Planet project.
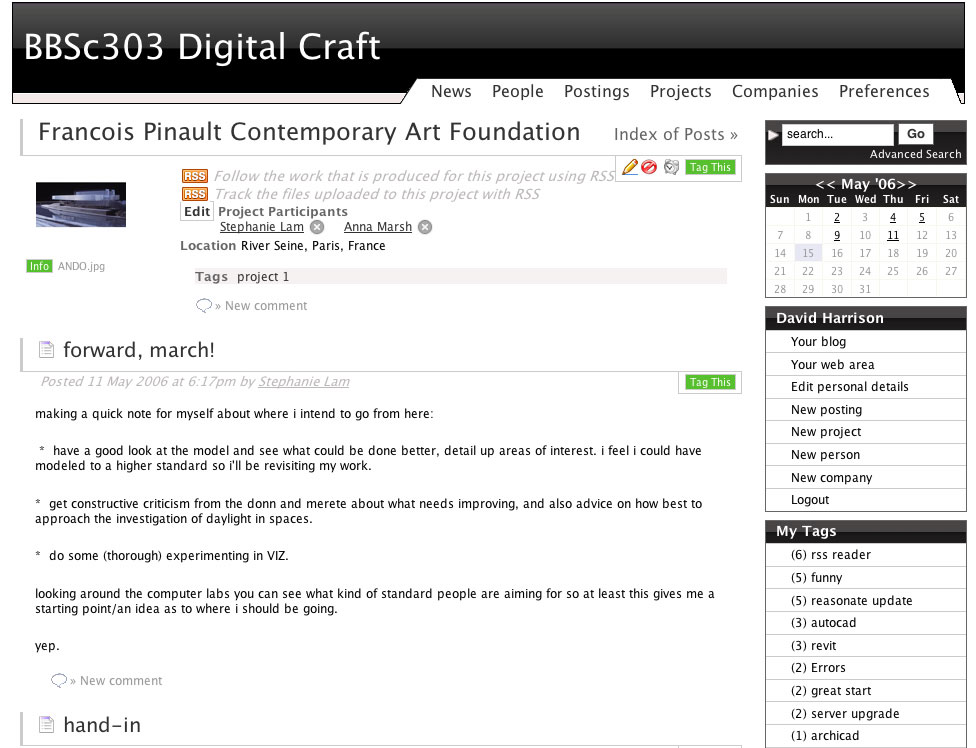
The aggregated project blog (click to enlarge)
Blog posts
The primary form of data entry was through blog posts. The interface provided a Javascript based WYSIWYG HTML editor (TinyMCE). The HTML editor provided the ability for students to set font and colour characteristics and easily insert tables, hyperlinks, tables and lists. One feature not included was a spelling checker as at the time this was seen as superfluous to requirements. In practice however a spelling checker probably would have been appropriate given the often poor quality of grammar employed by students.
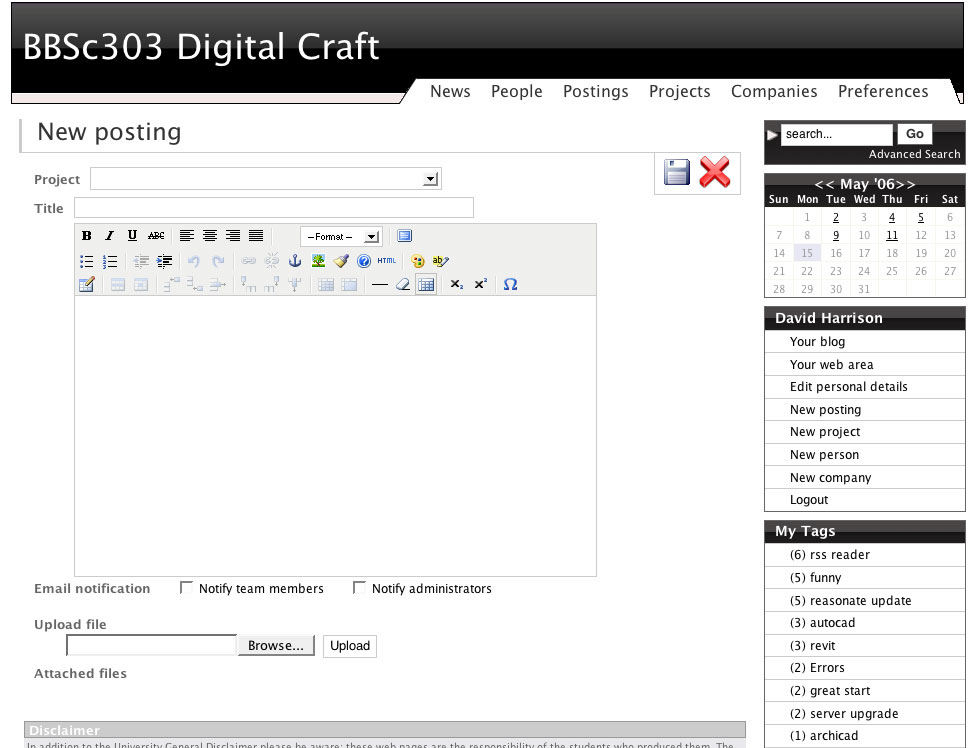
The new post interface of Reasonate (click to enlarge)
Uploading of files to posts
Digital design is a file-based process so the simple uploading of files was viewed as necessity. The upload process utilised the email philosophy of ‘attachments’ rather than embedding file links directly within the HTML posts. When students uploaded a file a basic form of versioning was employed, the file was saved on the server with a datestamp preceding the real filename. This allowed multiple versions of the same file to be uploaded without naming conflicts occuring. Within the Reasonate database a file entry was created that linked the datestamped file with the original filename. Project files of the same name were considered to be different versions of the same file and within the Reasonate interface it was possible to view and navigate between the different versions of the same file.
Tagging of blog posts
Tagging was employed as the second level of semantic categorisation above the basic project construct. Tags could be applied within the system to all pieces of data (blog posts, people, files, projects). The interface employed an AJAX mechanism that allowed tags to be added relatively quickly. During the tagging process dropdown list of tags were displayed that matched the letters already typed by the user (predictive tagging).
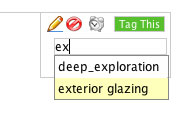
The tagging system in Reasonate
The mechanism employed had a number of issues. Firstly the suggestion system was very basic and relied on initial user input to provide suggestions. This of course required the user to have a fairly good idea of what they wanted to tag in the first place. Del.icio.us employs a much more intelligent system where tags can be suggested to the user prior to any input being entered. This suggestion system however requires a unique fingerprint (in del.icio.us’s case the unique URL) and a large body of fingerprints/tags to search against. Within Reasonate this large body of fingerprint/tag combinations does not exist to search against plus the posts themselves hold very little characteristic information in order to automatically suggest tags based on the subject’s content.
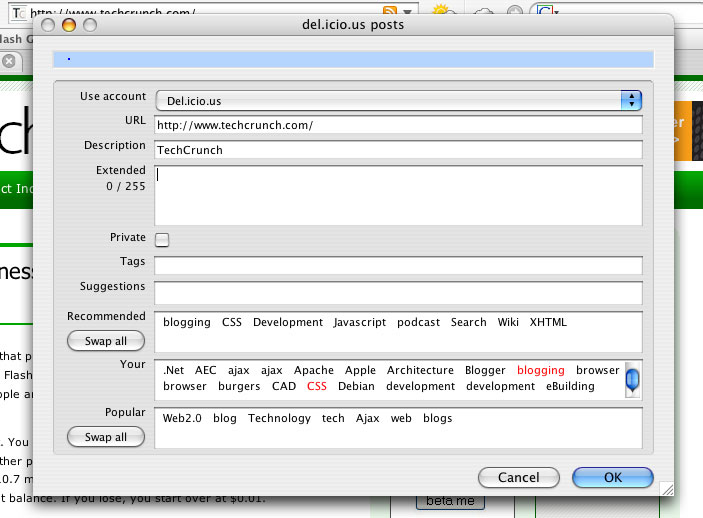
The del.icio.us extension for Firefox showing tag suggestions (click to enlarge)
An interface issue was the fact tags could not be added to content as it was created. This was an application issue as the underlying tag data-structure required content to exist before a tag could be associated with it. This interface issue made tagging rather convoluted, content had to be created and then tagged in a two step process. A far more efficient and user-friendly process is to have content creation and tagging all part of a single step process.
Another interface issue was the single entity nature of tagging. Rather than using a basic text field and adding tags as a comma delimitated set of words tags were added one by one. In hindsight whilst arguably more aesthetically pleasing this process was slow and disjointed compared to the simple data-entry mechanism that is a text-field.
Finally yet another limiting interface issue was the minimal tag browser interface employed in the first half of the testing process. Rather than tag clouds or different lists showing personal, project and class tag lists the initial interface only listed a users personal tags and next to it a number indicating how many posts had been tagged with this item. This was very limiting from a functionality perspective as it did not allow for the simple browsing of team tags or relate this information to how the individual was using tags. These information issues came down to development time (or lack of it) and the necessity to develop other pieces of functionality such as the search engine before coming back to reassess user interface characteristics.
Indexing and searching of blog posts, tags and files
The search index used Ferret, a port of the Java Lucene search engine to Ruby (with a C search indexer backend). The search engine is very capable and allowed for different weighting of fields (tags given precedence), full text indexing of content and a complex boolean search query language. Overall implementation of the search engine went well and the resulting search capabilities were simple yet powerful. The degree to which this functionality will be used in the test environment is uncertain however given the short term nature of the project and limited quantity of data employed by the students.
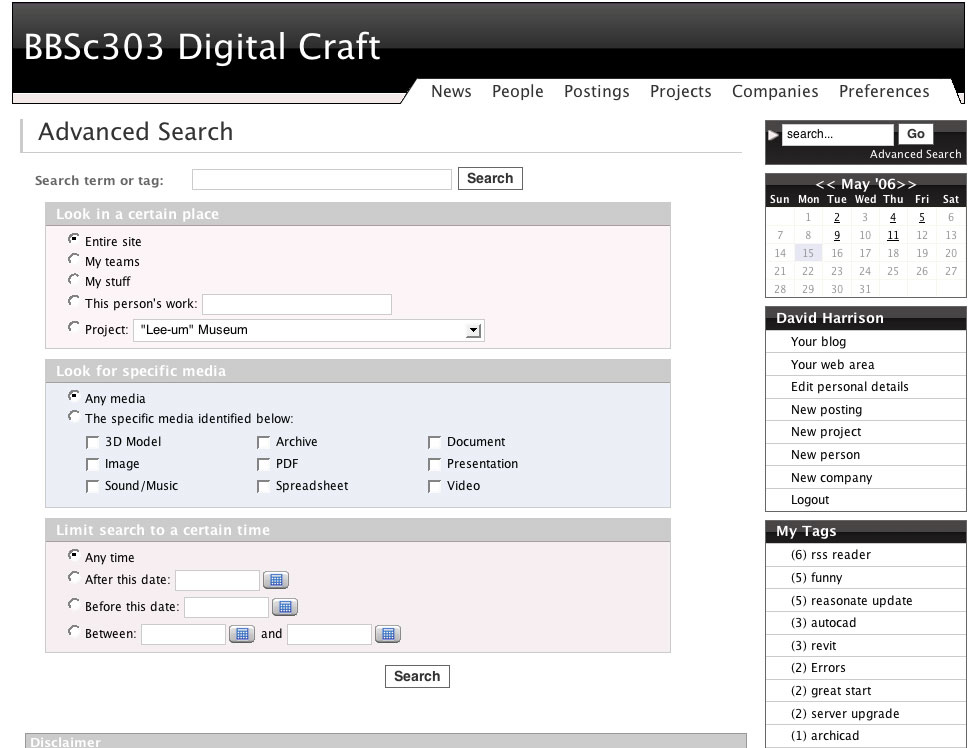
The Reasonate advanced search interface showing the different options for finding things (click to enlarge)
RSS feeds of blogs and search results
All aspects of the Reasonate system are RSS enabled. Feeds can be generated for student and project output, search results, use of tags and changes to a particular file. Application of this functionality within the course was limited by two factors. Firstly most of the students worked side by side and as a result did not need to utilise RSS functionality in order to understand the progress of their team.
Secondly there was a technical issues regarding the use of RSS readers in the University and other locations. At the University RSS bookmarks were deleted when students logged out of their workstation. Consequently using RSS soon became a chore as each time the students logged in they were required to recreate their RSS bookmarks. In many other locations (such as office workplaces) students were not allowed to install third party software (Firefox/Sage) and as a consequence it was felt RSS could not be used. After these issues were brought to light a few online RSS readers (Newsgator/GReader) were illustrated to the students as a means of tracking project work.
RSS was very successful from an administration perspective however because both Mike and myself had well established RSS software and reading habits. Consequently it was easy to keep an eye on student output which assisted in the early identification of problem areas and low output students. From this teaching/supervising perspective RSS was very interesting. Rather than meeting with students at a specific tutorial time there was a greater sense that work was being evaluated continuously 'on-demand' so to speak. Following through with such a concept could be a very interesting way to run tutorials in the future, rather than paying tutors to be present at a certain place for a period of time emphasis could be placed on RSS based tutor support. Half a tutors time could be spent in physical tutorials whilst the remainder allocated for solving problems as they occur online.
Hierarchical commenting to blogs.
Easy commenting was important in order to establish a platform for post blogging discussion. Many blog posts require either some form of clarification or discussion between users following the initial action of posting to the service. The commenting system employed was hierarchical in order to distinguish between different discussion threads on the same blog post. I was concerned that comment threads could change subject or be commandeered by another user to promote ideas not related to the original post. To counteract this threat the comment field was kept relatively small in size in order to give the visual impression that comments should be quick and to the point.
Another feedback mechanism discussed but not yet implemented in the test environment is the concept of a Trackback. A trackback is a completely new blog post by another user (or the same user) related to the ideas of the original post. The new post notifies the original post of their actions through the use of a simple ‘ping’ action. This action notifies the original blog of the new post, its author and url. The system tracks these Trackbacks and displays them as a list of hyperlinks following the post. At this point in time Trackbacks have not been implemented and given that there is no demand from students for such a service they will not be added to the test environment. From a pragmatic perspective the hardest part about Trackbacks is not the technical implementation but explaining to users how and when such a feature should be used. The concept is difficult for many technologically savvy users to understand, let alone explain to a class of students who have only just begun publishing content to the Web.
Implementing the test environment
Most of the Reasonate functionality was in place at the start of the course (late February) after a brief but intense development period in late January. Commenting and search functionality where not introduced until mid-April primarily because for the opening month the emphasis was on getting the posting and project mechanisms working correctly.
For the first six weeks Reasonate was hosted on one of my own servers whilst the core system was built and the majority of the bugs ironed out. For the most part this hosting went well apart from a few Internet outages and one major hardware failure. Bandwidth was stretched in the final week of hosting as students, unaccustomed to the low-bandwidth nature of the Internet struggled to upload multiple 20-30 megabyte Powerpoint files to the server.
Following this period Reasonate was moved to an upgraded School of Architecture server. This move removed the bandwidth bottleneck but made management and regular backups slightly more difficult.
During this testing regular nightly backups were taken of the Reasonate database to allow for time-based analysis of data entry activity and usage trends at a later date.
Uptake
Students were slowly introduced to the Reasonate concept over a few weeks during the introductory tutorial process. A questionnaire for the students past computer experience has not been carried out but it is planned in the near future. From past experience however most students have little or no Web knowledge at the beginning of the course (learning about the Web is a primary factor for taking the course). Given this limited base of experience students were quick to take up the blogging aspect of Reasonate. For the tutorial process lasting three weeks most students averaged approximately four blog posts whilst some did far more.
After the initial phase of testing the following functionality requirements also became apparent:
Email notification of new blogs and comments
Students knew RSS feeds were available to the course co-ordinators and as a consequence assumed any piece of content they published was immediately read by those in charge or in their group. Consequently some important questions posed in blog content were not answered as quickly as possible by Mike and I. In our defense we were suffering ‘information overload’. 50+ students plus 30-40 other sites content is a lot of RSS content to parse and respond to regulary, especially when faced with a similar number of other communicae (in the form of emails, meetings, instant messages, mobile phone txt’s). Also it was found that in order to undertake digital conversations with or between students data had to be entered twice, once with the comment post and a second short email saying a comment had been posted. Otherwise the alternative was to just send an email and bypass the test system. In practice a method of capturing email collaboration would be the preferred solution but in the testing environment it was ideal for most Reasonate specific conversation to travel through the comments mechanism and be captured for later analysis. To satisfy these needs email notification of comments was added to provide the best blend of email’s ability to alert people and Reasonate’s capability to capture and search conversation.
WebDAV support for the project hand-in on student produced mini-websites
This capability was very course specific and added in order for students to create their own mini-websites and have them easily published to the Internet. In practice such a system would be of limited practical use and in many respects actually worked against the underlying principles of blogging where normal people do not have to worry about such things as Web naming conventions and html standards.
Whilst perhaps superfluous to the ultimate goal I did like the way WebDAV seamlessly integrates onto the users desktop (all the major operating systems support WebDAV file shares). This coupled with a versioned file-attachment system for blog posts would be very useful. In practice the WebDAV share would need to be read-only as the spec and its implementations do not provide for on the fly versioning of files but even then a file browser view of the latest project files as uploaded by participants would ease usability.
Wrap-up functionality to allow the simple aggregation of multiple blog posts into a cohesive story
This functionality is very important, so important in fact I will be giving this one its own post on this blog. Thinking about this started when a couple of things occurred. Firstly it was observed that most students were using the blogging system as a form of virtual scrapbook. Whilst most were blogging very regularly their posts were not a cohesive or descriptive as one would have imagined. In fact for the most part blog usage was quite different to general blogs you see on the web today. Rather than larger posts on a single subject many students blogs resembled stream of conscious thought process in a highly conversational (email) style. This was not a ‘bad thing’, we had on purpose left students free to develop their own blogs. Rather than returning with the more conventional long-hand style writing as employed conventionally the students had, either subconsciously or through peer observation, developed a very brief (one/two sentence) prose.
Mike’s observation at this was that he was not going to read through all these tiny posts in order to mark the project at the end. Initially we discussed using the student’s basic html web page submission as the venue for the summary texts for the blog but after a bit of thought this just felt wrong. The intention of Reasonate was to capture the design development process and to a certain degree we had. Ironically what we had captured was like any design development process, fragmented, terse and by itself not enough to understand the overall objectives, processes and achievements associated to the endeavour. What was needed was a mechanism easily ‘wrap things up’ into a format that was easily disseminated by the casual observer yet retained the rich chronological underpinnings the blogging process had successfully established….